In addition to all that, you can add spider and downloader middlewares in between elements as it can be Go to this website seen in the diagram below. The code is really simple however there are several efficiency and also functionality concerns to address before effectively creeping a total site. Typical Crawl preserves an open repository of web crawl data. As an example, the archive from May 2022 has 3.45 billion web pages. Search engines (e.g. Googlebot, Bingbot, Yandex Robot ...) collect all the HTML for a substantial part of the Internet. Another point to note is that this crawler will certainly obtain the web pages from the home page, however will not proceed creeping besides those web pages have actually been logged.
- To comprehend exactly how to apply Beautiful Soup to real-life jobs, ensure to check our "Just how to scrape information in Python utilizing Beautiful Soup" tutorial.
- Although the applications of internet spiders are almost unlimited, large scalable crawlers have a tendency to come under one of numerous patterns.
- Provide your spiders an unreasonable benefit with Crawlee, our preferred library for developing reliable scrapers in Node.js.
- Although it is easy to manage, it can not scrape photos or crawl data on a large scale.
- Data crawling is done on a massive scale that needs extra safety measures so as not to offend the resource or break any kind of laws.
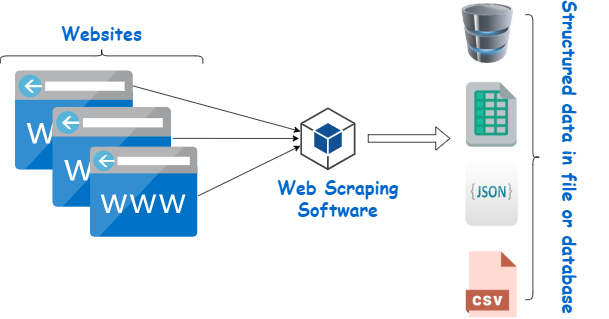
It obtains the HTML web pages, parses them making use of the Cheerio Node.js collection as well as allows you remove any kind of information from them. Internet scratching is the art of leveraging the power of automation to open the web and also extract structured web data at range. The data accumulated can after that be used for countless applications, such as training equipment finding out algorithms, price tracking, market research, list building, and extra. To do this, you'll construct a web scrape to essence cost information from several sites for this tutorial. The scraper will accumulate all the cost information so that it can be analyzed and compared later on. This is a fantastic foundation for constructing a rate sharp service, and even a scalping crawler you can utilize to buy products in limited supply.
Learn
Abigail Jones Today, large information has actually been extensively utilized in different locations like e-commerce websites, social networks, clinical reforms and also monetary records. Although there are lots of statistics companies to give various databases, special requirements are not normally thought about by such organizations. People or enterprises desire more information like the certain cost of the item or the contact info of different websites. That might be the ground of the internet site data scraping solution. You could now find there are lots of website data removal tools available online like Import.io and Octoparse.
Is it lawful to crawl data?
Internet scuffing as well as creeping aren't unlawful by themselves. Besides, you can scuff or crawl your very own web site, without a hitch. Startups like it due to the fact that it''s a cheap and also powerful means to collect data without the requirement for collaborations.
Individual agents allow the web server you wish to scuff to comprehend which internet browser, running system, or device you are using. You will recognize your ID in the way the browser's user representative layout you made use of in your link requests. Nevertheless, the server will find as well as outlaw you if you make several requests to the server with the exact same individual representative. To avoid being blocked, use a major browser's user representative as well as alter it often. Robots.txt permits or denies access to Links on a web site to restrict the crawl rate. When an internet site spots an internet spider, it will blacklist IP addresses to stop their sites from being crept.
Crawlee
Continuing with the previous instance, when you look for web creeping vs. web scuffing, the search engine crawls every one of the internet's websites, consisting of pictures and videos. Internet search engine utilize internet spiders to creep all pages by adhering to the links embedded on those pages. Internet spiders discover new web links to other Links as they creep web pages as well as include these discovered web link to the crawl line up to creep following.
Mobility recorded by wearable devices and gold standards: the ... - Nature.com
Mobility recorded by wearable devices and gold standards: the ....
Posted: Thu, 19 Jan 2023 08:00:00 GMT [source]
The previous phase showed numerous techniques of crawling through web sites and also finding new web pages in an automatic means. Nevertheless, I believe that the power and also family member versatility of this approach more than makes up for its genuine or viewed shortcomings. However, the data version is the underlying foundation of all the code that utilizes it. A bad choice in your version can quickly cause issues writing as well as preserving code down the line, or difficulty in removing and also efficiently utilizing the resulting data.
Scratching A Site With Nodejs
You will certainly discover to utilize CSS selectors as well as XPath expressions to remove purposeful data from HTML documents. IMDb redirects courses under/ whitelist-offsite and/ whitelist to outside domain names. There is an open Scrapy Github problem that reveals that external URLs don't get strained when OffsiteMiddleware is used before RedirectMiddleware. To repair this issue, we can set up the link extractor to skip Links starting with two regular expressions.
Now we can utilize that feature scrape_guardian_article in any type of various other component of our manuscript. We utilize a running variable i, taking values from 1 to size to access the single web links in all_links and write some development result. I wished this post on information scratching was fascinating and amazing. There are limitless possibilities regarding what you can achieve with web and also information scratching. While reviewing this write-up you've most likely questioned, "what are some good usage cases for web/data scraping?
Exactly How Are Marketing Professionals Making Use Of Information Scraping?
On the other hand, Python might be your ideal option if you are also interested in data scientific research as well as artificial intelligence. These areas greatly benefit from having accessibility to huge collections of information. Therefore, by grasping Python, you can acquire the essential data via internet scratching, procedure it, and after that straight use it to your task. Cheerio Scrape is a ready-made service for creeping web sites using plain HTTP demands.
https://maps.google.com/maps?saddr=619-2%20Carlton%20St.%2C%20Toronto%2C%20ON%20M5B%201J3%2C%20Canada&daddr=2%20Bloor%20St%20W%2C%20Toronto%2C%20ON%20M4W%203E2%2C%20Canada&t=&z=15&ie=UTF8&iwloc=&output=embed
If you've ever duplicated and also pasted material from an internet site into a various location, you are doing a very hands-on version of information scuffing. In this post, we will be using software application applications to do the information scuffing for us. Utilizing among the techniques or devices described previously, produce a data that utilizes a vibrant website question to import the details of products listed on your site. Attempt searching for a checklist of helpful calls on Twitter, as well as import the data making use of data scratching. This will certainly offer you a preference of just how the procedure can match your day-to-day work. FeedOptimiseoffers a variety of information scraping and also data feed services, which you can find out about at their internet site.
Scientists develop 'wildDISCO' method to detect tiny cancerous tumors - Interesting Engineering
Scientists develop 'wildDISCO' method to detect tiny cancerous tumors.
Posted: Tue, 11 Jul 2023 13:39:00 GMT [source]
What is the difference in between ditching and also creeping?
Internet scraping aims to draw out the information on website, and also internet creeping functions to index as well as find websites. Web crawling includes complying with web links completely based upon hyperlinks. In contrast, web scuffing implies writing a program computer that can stealthily gather information from several web sites.